Semantic Segmentation — Full-Scene Parsing
Pixel-level scene understanding for autonomous navigation — every pixel classified into road, sidewalk, vehicle, pedestrian, sky, vegetation, and infrastructure classes. Ongoing internal pilot on self-hosted CVAT.
The Challenge
Autonomous navigation systems don’t just need to detect objects — they need to understand the entire scene. Where is the road? Where does the sidewalk start? What’s sky and what’s a building? Semantic segmentation assigns a class label to every single pixel in an image, giving perception models complete scene understanding.
This is an ongoing internal pilot that serves two purposes: training new annotators on one of the most demanding annotation types in computer vision, and building a production-ready portfolio that demonstrates TechAI Remote’s semantic segmentation capability to prospective clients. Every new cohort of annotators works through this project as part of their training pipeline.
Technical SpecificationsAnnotation Details
What Is Semantic Segmentation
Unlike bounding boxes (rectangles around objects) or polygon segmentation (outlines around individual instances), semantic segmentation classifies every pixel in the image. The output is a color-coded mask where each color represents a different class — road surface, vehicles, pedestrians, buildings, sky, vegetation, traffic signs, and more. No pixel is left unlabeled.
Scene Classes
| Class | Description |
|---|---|
| Road | Drivable surface, lane markings |
| Sidewalk | Pedestrian walkways, curbs |
| Vehicle | Cars, trucks, buses, motorcycles |
| Pedestrian | People walking, standing, crossing |
| Building | Structures, walls, facades |
| Vegetation | Trees, bushes, grass, plants |
| Sky | Open sky, clouds |
| Infrastructure | Poles, signs, fences, barriers |
Infrastructure
| Component | Detail |
|---|---|
| Platform | CVAT v2.58.0 (self-hosted) |
| Server | Hetzner dedicated server |
| Deployment | Docker with SSL |
| Data Security | Data never leaves our server |
| Purpose | Training + portfolio building |
Export Formats
| Format | Use Case |
|---|---|
| Cityscapes | Urban driving segmentation |
| COCO Panoptic | Combined semantic + instance |
| PNG Masks | Per-class color-coded masks |
| CVAT JSON | Client CVAT import |
Annotation in Production
Real screenshot from our self-hosted CVAT instance showing semantic segmentation on an urban driving scene. Every pixel is assigned to a class — the color-coded overlay shows how road, vehicles, pedestrians, buildings, vegetation, and sky are all parsed into distinct segments.
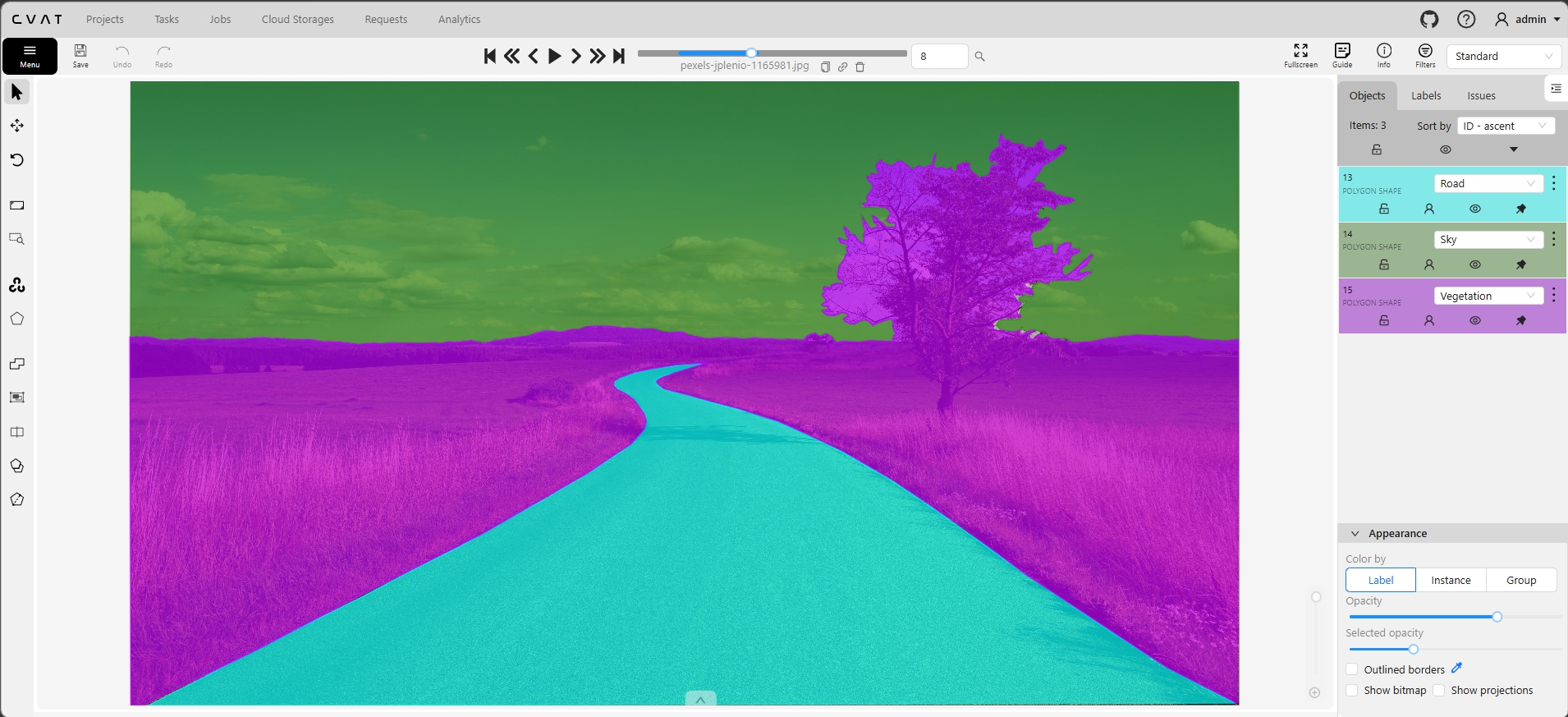
Full-scene semantic segmentation in CVAT: every pixel classified into scene classes. Color-coded overlay shows road surface, vehicles, pedestrians, buildings, vegetation, sky, and infrastructure all labeled at pixel level.
Why Full-Scene Parsing Matters
Beyond Object Detection
Object detection tells you what’s in the scene. Semantic segmentation tells you what every part of the scene is. An autonomous vehicle needs to know not just “there’s a car ahead” but “this is road I can drive on, this is sidewalk I can’t, this is sky above, and this is a building boundary.” Full-scene understanding is the foundation of safe autonomous navigation.
The Annotation Challenge
Semantic segmentation is the most labor-intensive annotation type. Every pixel must be classified — no gaps, no unlabeled areas. Boundaries between classes (where road meets sidewalk, where building meets sky) must be pixel-precise. A single image can take 30–90 minutes to annotate correctly, compared to 1–3 minutes for bounding boxes.
Training Pipeline Value
This is why we use semantic segmentation as our advanced training module. Annotators who can handle full-scene parsing at pixel level can handle any annotation type. It builds spatial reasoning, attention to detail, and class boundary judgment that transfers directly to every other annotation skill — from polygon instance segmentation to 3D cuboid placement.
Autonomous Navigation Use Cases
Drivable area detection (what surface can the vehicle safely traverse), lane understanding (where are the lane boundaries and what type are they), obstacle mapping (what’s in the path and what class is it), and scene context (urban vs. highway vs. suburban environments). All of these require pixel-level scene parsing.
Why this is an ongoing project: Every new cohort of annotators at TechAI Remote works through semantic segmentation as their advanced training milestone. The project continuously grows as we recruit and onboard new team members. This means our semantic segmentation capability scales with our team — every annotator has proven they can handle the hardest annotation type before being assigned to client work.
How We Approach Semantic Segmentation
Annotation Workflow
- Scene assessment: Annotator reviews the full image to identify all present classes and plan the labeling order
- Large regions first: Sky, road, and building areas painted first to establish the scene structure
- Detail refinement: Vehicles, pedestrians, vegetation, and infrastructure layered on top with precise boundaries
- Boundary precision: Zoom to 300%+ for pixel-level accuracy at class transitions (road/sidewalk, building/sky)
- Completeness check: Every pixel accounted for — no gaps between classes, no unlabeled regions
Quality Assurance
- Stage 1 — Self-check: Annotator zooms through the entire image verifying boundary precision and class accuracy
- Stage 2 — Peer review: Second annotator checks for missed regions, incorrect class assignments, and boundary errors
- Stage 3 — QA Lead final: Ibrahim Ouma validates overall quality with focus on ambiguous boundaries and rare classes
- Boundary tolerance: Class boundaries accurate within 1–2 pixels
- Coverage: 100% pixel coverage — zero unlabeled pixels
- Overall QA target: 98.5% accuracy across all labeled pixels
Who This Serves
Semantic segmentation supports teams building:
- Autonomous vehicles: Drivable area detection, lane parsing, and full scene understanding for L2–L5 systems
- Mobile robotics: Navigable surface identification for indoor and outdoor robots
- Drone navigation: Terrain classification and obstacle mapping for UAV flight planning
- Urban planning: Land use classification, green space mapping, and infrastructure analysis from street-level imagery
- ADAS: Advanced driver assistance features requiring real-time scene understanding
Production-ready on demand: While this is an ongoing training project, the capability is production-ready. Our annotators are trained, our QA pipeline is proven, and our CVAT infrastructure handles semantic segmentation at scale. If your perception team needs full-scene parsing, we can start a pilot immediately.
Need Semantic Segmentation?
Full-scene pixel-level parsing for autonomous navigation, robotics, or any domain. Start with a free pilot — same CVAT infrastructure, same QA pipeline, same 98.5% accuracy guarantee.