Bounding Box — Multi-Domain Object Detection
25,000+ bounding box annotations across 6 clients and multiple domains — pedestrians, vehicles, aerial views, and urban scenes. All annotated on self-hosted CVAT.
The Challenge
Bounding box annotation is the foundation of object detection — every autonomous vehicle, security system, retail analytics platform, and drone perception pipeline starts here. But quality varies dramatically across providers. Tight bounding boxes with consistent class labels across thousands of images, multiple domains, and varying conditions is where most annotation teams fall apart.
TechAI Remote has delivered 25,000+ bounding box annotations across 6 different clients, in-house pilots, and self-training projects — spanning pedestrian detection in crowded street scenes, vehicle detection from aerial and ground-level views, and multi-class object detection in urban environments. Every annotation was produced on our self-hosted CVAT instance with full three-layer QA.
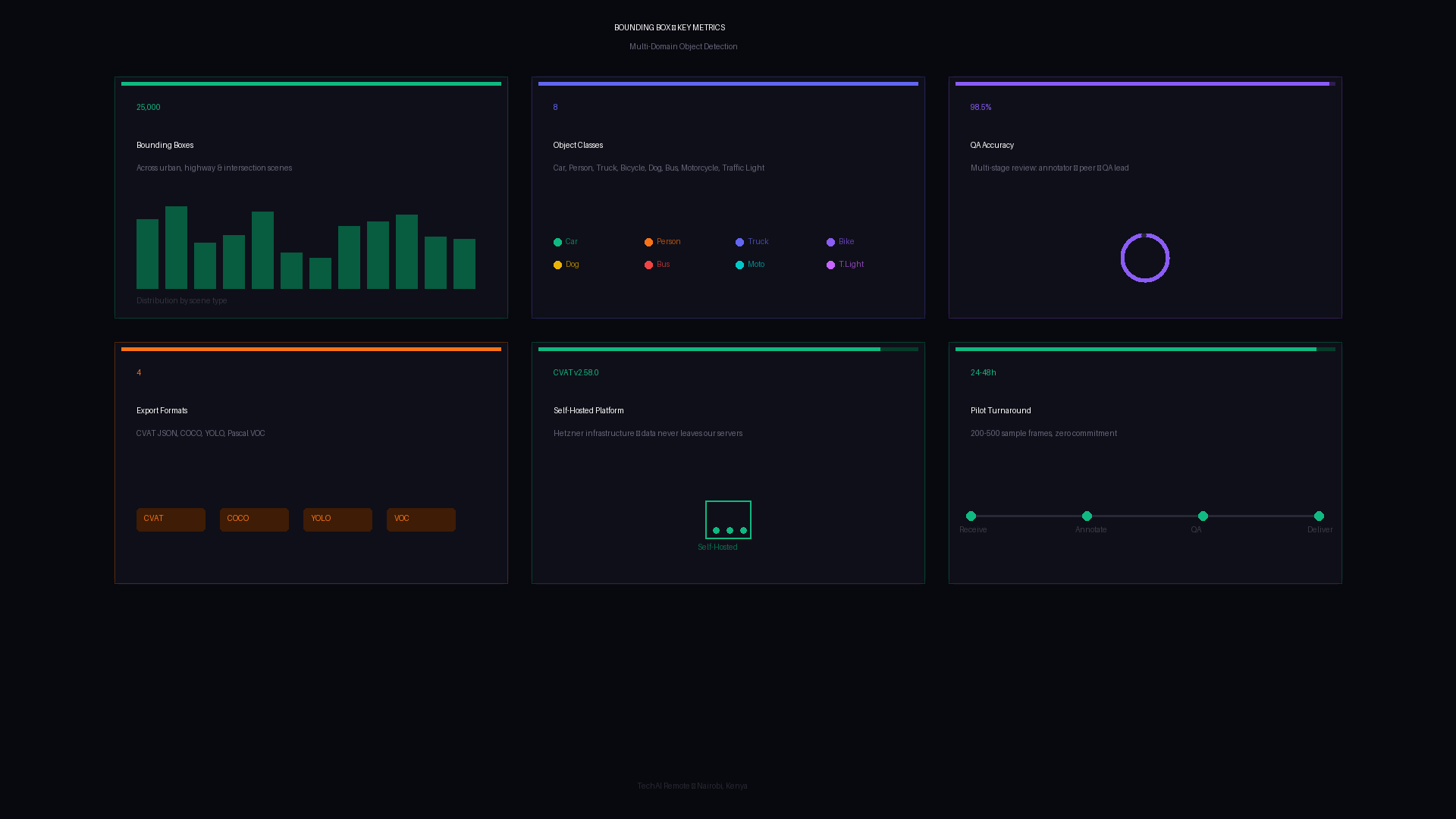
Project metrics: 25,000+ bounding box annotations, 6 clients, multiple domains, self-hosted CVAT, 98.5% QA accuracy
Technical SpecificationsDomains & Object Classes
Annotation Domains
Bounding box work spanned multiple visual domains — each with its own challenges in scale, occlusion, density, and perspective. From street-level pedestrian crowds to overhead aerial vehicle detection, every domain requires different annotation strategies and edge case handling.
Object Classes
| Class | Domain |
|---|---|
| Person | Street scenes, crosswalks, crowds |
| Vehicle | Aerial views, parking lots, roads |
| Pedestrian | Urban intersections, sidewalks |
| Cyclist | Road scenes, bike lanes |
| Traffic Sign | Street-level detection |
| Custom Classes | Per-client specifications |
Infrastructure
| Component | Detail |
|---|---|
| Platform | CVAT v2.58.0 (self-hosted) |
| Server | Hetzner dedicated server |
| Deployment | Docker with SSL |
| Data Security | Data never leaves our server |
| Access | NDA-protected, role-based |
Export Formats
| Format | Use Case |
|---|---|
| COCO JSON | Standard object detection training |
| YOLO | Real-time detection models |
| Pascal VOC | Legacy detection pipelines |
| CVAT JSON | Client CVAT import |
Annotation in Production
Real screenshots from our self-hosted CVAT instance showing bounding box annotation across different domains. Each image shows the annotation canvas with labeled bounding boxes, the objects panel with class labels, and the color-coded overlay system for visual verification.
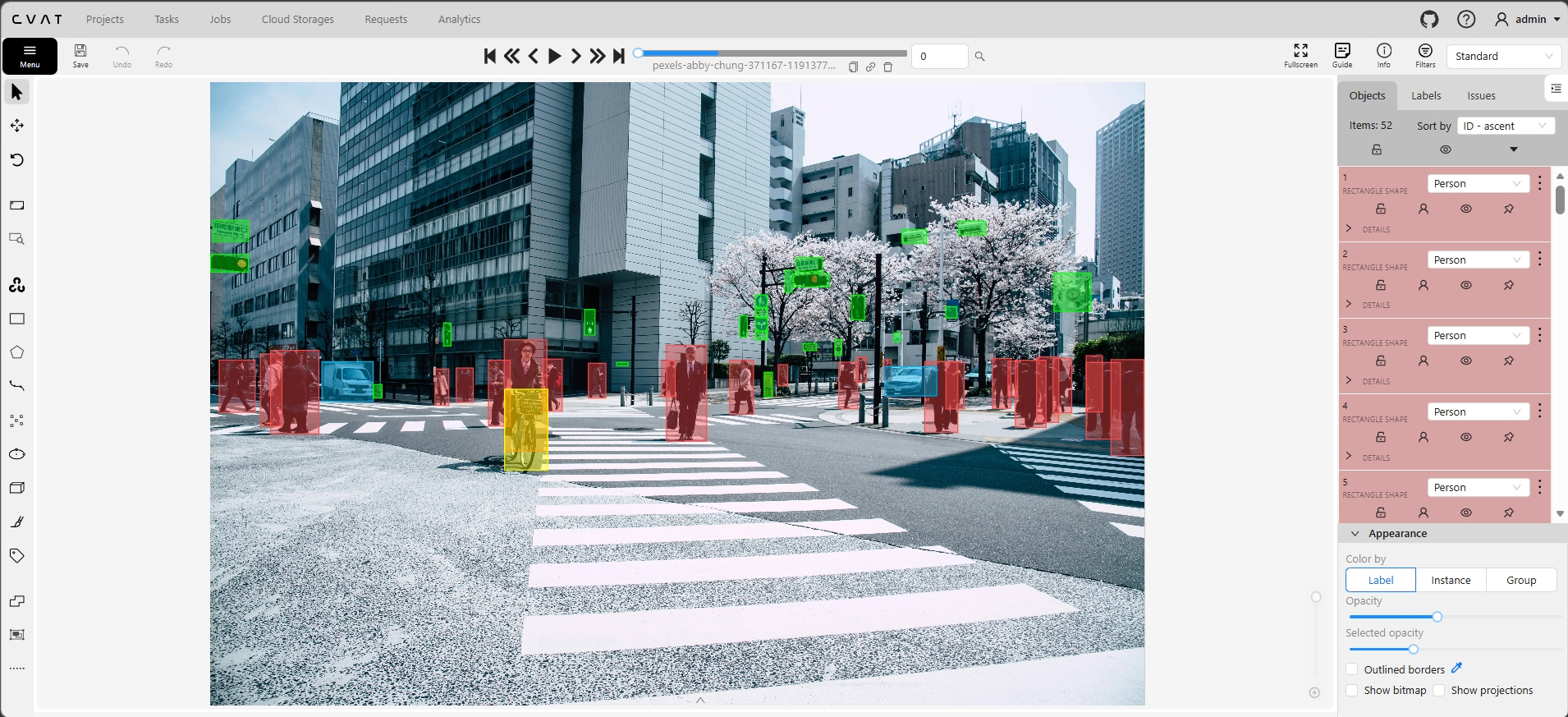
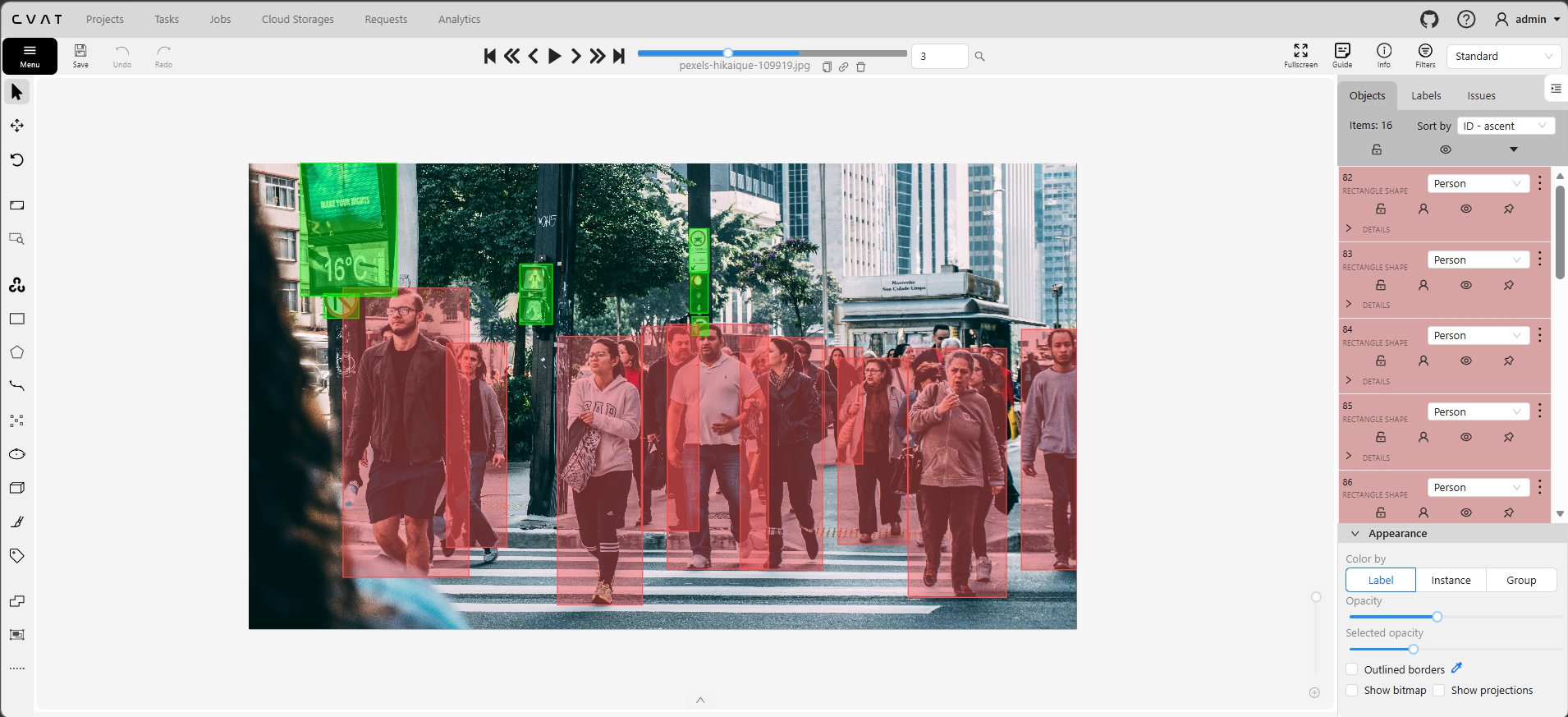
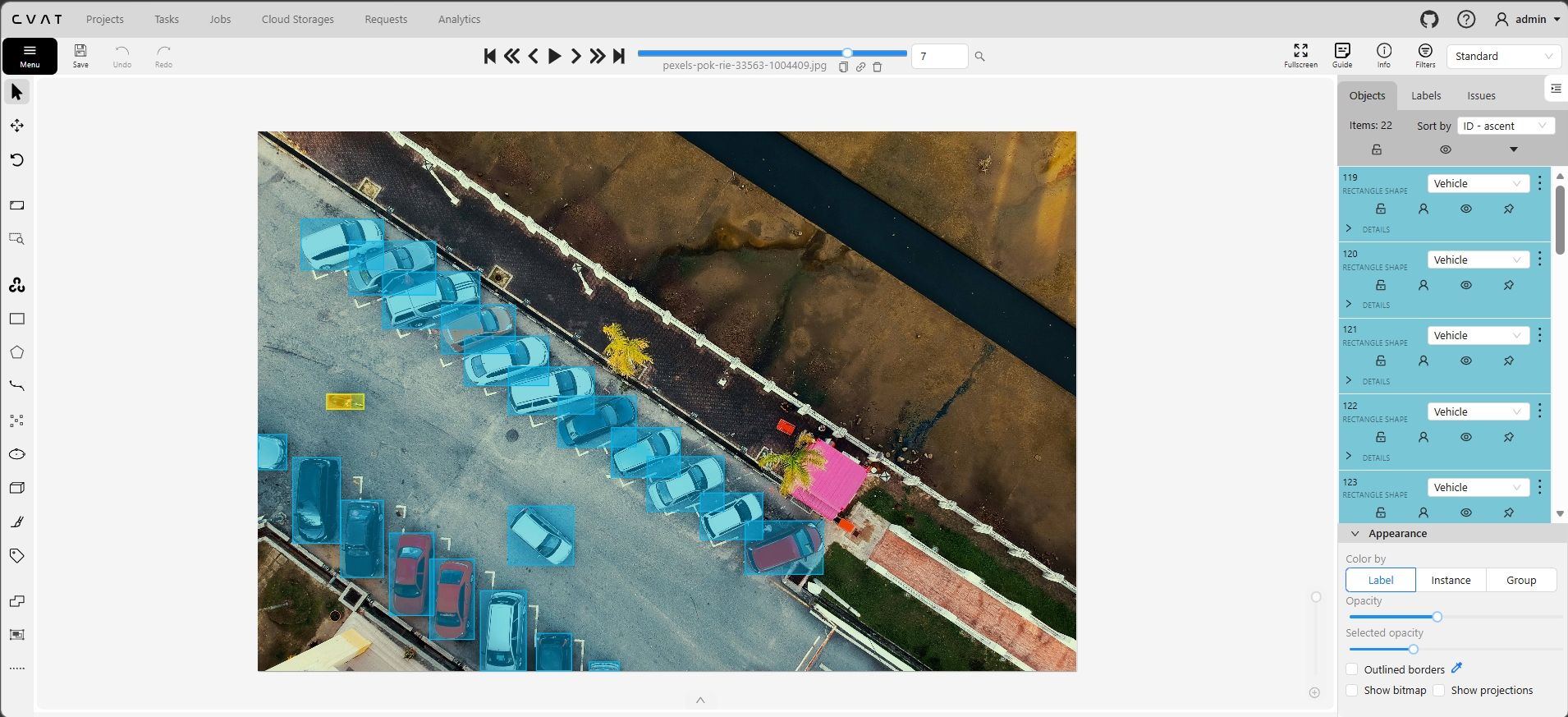
Left: Dense urban scene — 52 person bounding boxes in a crowded crosswalk with heavy occlusion. Center: Street-level pedestrian detection — 16 persons with varying scale and partial visibility. Right: Aerial vehicle detection — 22 vehicles in a parking lot from overhead perspective.
Why Multi-Domain Matters
A single bounding box model trained on clean, well-lit images fails in the real world. Production object detection needs training data that spans perspectives, densities, lighting conditions, and object scales. Our 25,000+ annotations deliberately cover this range.
Street-Level Pedestrian Detection
Crowded urban crosswalks with 50+ persons per frame. Heavy occlusion where pedestrians overlap, varying scales from close-range to distant, and mixed lighting conditions. This is where most auto-labeling tools break down — distinguishing overlapping humans in dense crowds requires human spatial judgment.
Aerial & Overhead Views
Vehicle detection from drone and satellite perspectives. Objects appear at dramatically different scales and orientations compared to street-level views. Parking lots, intersections, and highway segments annotated from above — critical for surveillance, urban planning, and traffic monitoring applications.
Urban Mixed-Class Scenes
Street scenes containing multiple object classes simultaneously — persons, vehicles, cyclists, and infrastructure. Annotators must correctly classify each object while maintaining tight bounding box boundaries even when classes overlap in the frame.
Edge Cases Across Domains
Partial visibility at frame edges, extreme occlusion where less than 30% of the object is visible, scale variation within a single image (near objects 500+ pixels vs. distant objects under 20 pixels), and unusual poses or orientations. These are the annotations that separate production-grade datasets from hobbyist work.
Key insight: The hardest bounding boxes aren’t the obvious ones — they’re the partially occluded pedestrian behind a pole, the vehicle half-hidden by a tree in an aerial shot, and the cyclist at the edge of frame. Our annotators are trained to annotate what’s visible, classify correctly even with minimal visual evidence, and maintain consistency across thousands of images.
How We Deliver Bounding Box Projects
Annotation Workflow
- Client onboarding: Review annotation guidelines, class definitions, edge case rules, and export requirements
- Task creation: Images uploaded to self-hosted CVAT, split into batches, assigned to trained annotators
- Bounding box placement: Tight-fitting rectangles drawn around each target object with correct class label
- Edge case handling: Occluded objects, truncated objects at frame edges, and ambiguous classes flagged and resolved per guidelines
- Export & delivery: Annotations exported in client-specified format (COCO, YOLO, Pascal VOC, CVAT JSON)
Quality Assurance
- Stage 1 — Self-check: Annotator reviews own work for missed objects, incorrect labels, and loose bounding boxes
- Stage 2 — Peer review: Second annotator validates every box for tightness, class accuracy, and completeness
- Stage 3 — QA Lead final: Ibrahim Ouma performs final validation with spot-checks on box tightness and class distribution
- Consistency checks: Cross-image label consistency verified — same object type gets the same label every time
- Completeness audit: Random sampling to ensure no objects are missed, especially in dense scenes
- Overall QA target: 98.5% accuracy across all annotations
Who This Serves
Bounding box annotation is the entry point for most computer vision pipelines:
- Autonomous vehicles: Pedestrian, vehicle, and cyclist detection for ADAS and self-driving perception
- Security & surveillance: Person detection and tracking in CCTV and drone footage
- Retail analytics: Customer counting, foot traffic analysis, and shelf monitoring
- Aerial & satellite: Vehicle counting, infrastructure monitoring, and urban planning from overhead imagery
- Robotics: Object detection for pick-and-place, navigation, and obstacle avoidance
Why choose managed annotation over auto-labeling? Auto-labeling tools achieve 85-92% accuracy on clean, well-lit images with standard objects. But real-world datasets include occlusion, unusual angles, rare objects, and edge cases where automated tools consistently fail. Our 25,000+ annotations across 6 clients prove we handle the full spectrum — from easy frames to the hardest edge cases that break production models.
Need Bounding Box Annotation?
Start with a free 500-image pilot. Multi-domain, multi-class, any export format. Same CVAT infrastructure, same QA pipeline, same 98.5% accuracy guarantee.