3D LiDAR Point Cloud Annotation
5,000 KITTI frames annotated with 3D cuboids, 6 object classes, and camera-LiDAR sensor fusion. Self-hosted on CVAT v2.58.0 with Hetzner infrastructure.
The Challenge
Autonomous vehicle and robotics perception models need high-quality 3D ground truth data to detect and track objects in physical space. Unlike 2D bounding boxes, 3D cuboid annotation requires spatial reasoning — understanding object position, orientation, and dimensions within a point cloud, then cross-referencing with synchronized camera imagery for validation.
This pilot project demonstrated TechAI Remote’s capability to deliver production-grade 3D LiDAR annotation using the KITTI Raw dataset format — the industry standard benchmark for autonomous driving research. The goal: annotate 5,000 frames with 3D cuboids across 6 object classes, maintaining 98.5% QA accuracy while building the operational playbook for scaling 3D annotation services.
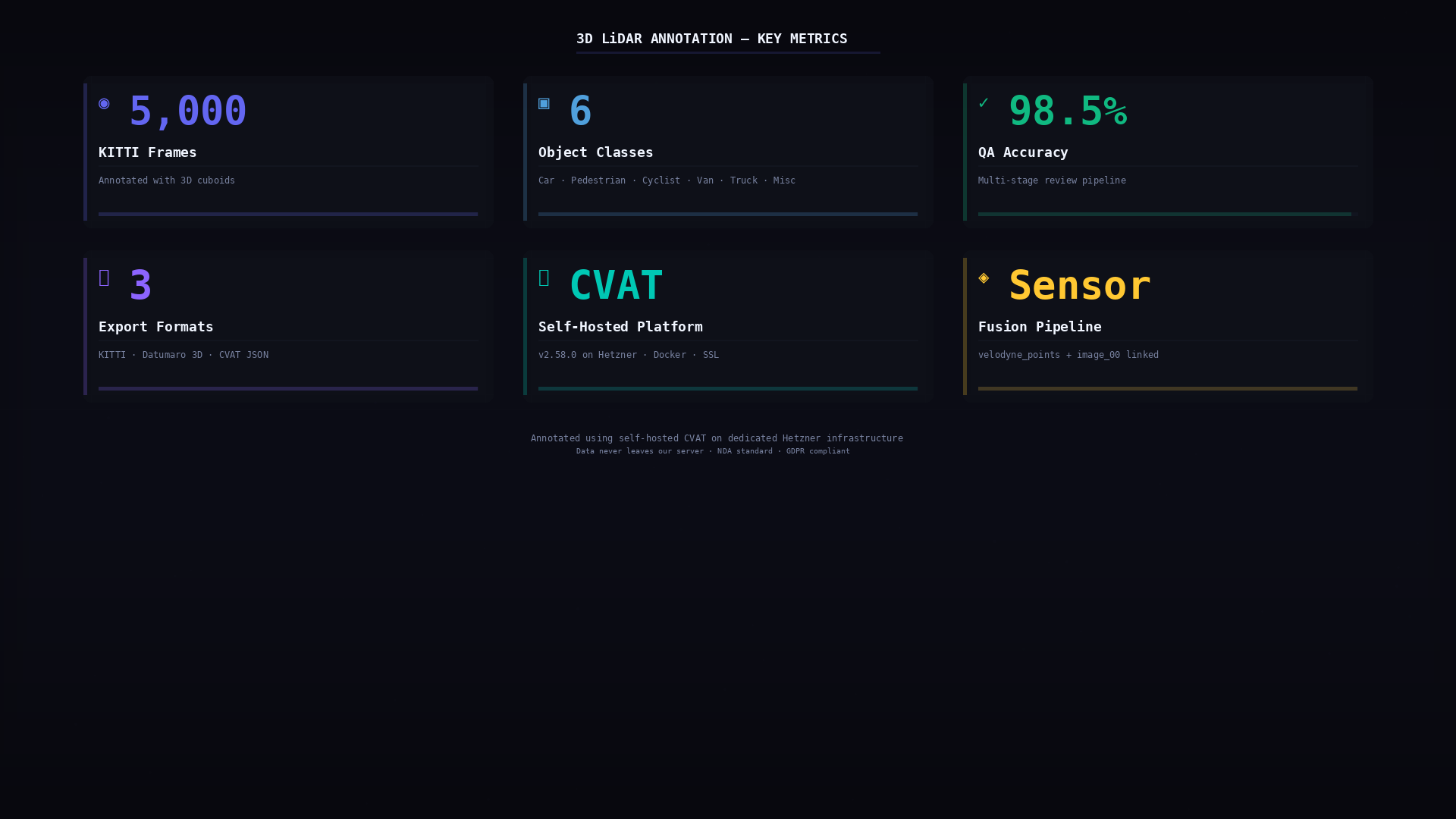
Key project metrics: 5,000 KITTI frames, 6 object classes, 98.5% QA accuracy target, 3 export formats, self-hosted CVAT infrastructure
Technical SpecificationsDataset & Pipeline
Data Format
KITTI Raw format with synchronized sensor streams. Each frame includes a velodyne_points .bin file (3D point cloud) paired with an image_00 .png file (front-facing camera). This sensor fusion pipeline enables annotators to cross-validate cuboid placement against both the 3D spatial data and the 2D visual context.
Object Classes
| Class | Description |
|---|---|
| Car | Passenger vehicles, sedans, SUVs |
| Pedestrian | Walking, standing, or crossing individuals |
| Cyclist | Bicycles with riders |
| Van | Cargo vans, minivans |
| Truck | Heavy vehicles, delivery trucks |
| Misc | Other road objects not covered above |
Infrastructure
| Component | Detail |
|---|---|
| Platform | CVAT v2.58.0 (self-hosted) |
| Server | Hetzner dedicated server |
| Deployment | Docker with SSL |
| Data Security | Data never leaves our server |
| Access | NDA-protected, role-based |
Export Formats
| Format | Use Case |
|---|---|
| KITTI 3D | Direct model training |
| Datumaro 3D | Format conversion pipeline |
| CVAT JSON | Client CVAT import |
Annotation in Production
Real screenshots from our self-hosted CVAT v2.58.0 instance showing 3D cuboid annotation on KITTI point clouds. Each frame includes the 3D viewport (top, side, front projections), synchronized camera context image, and the objects panel with class labels and cuboid properties.
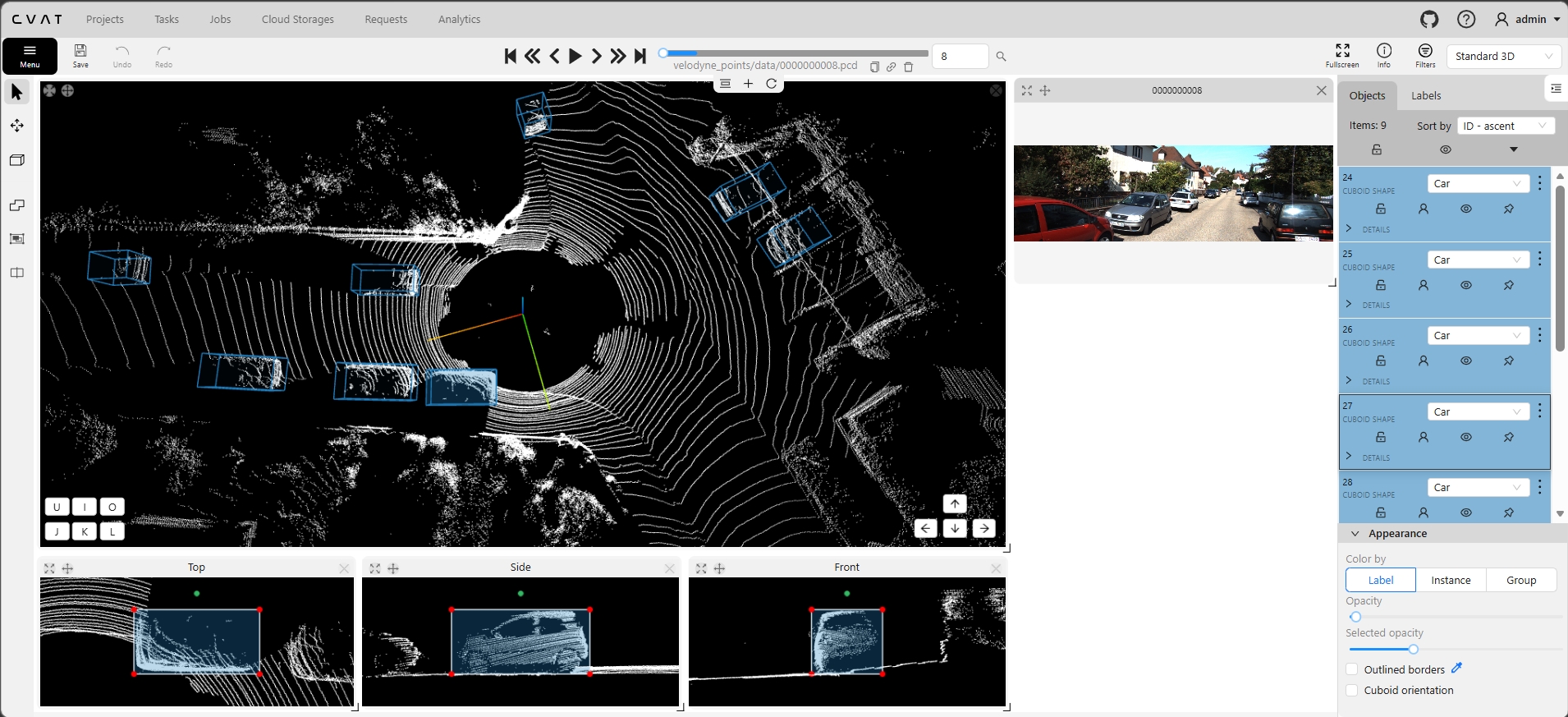
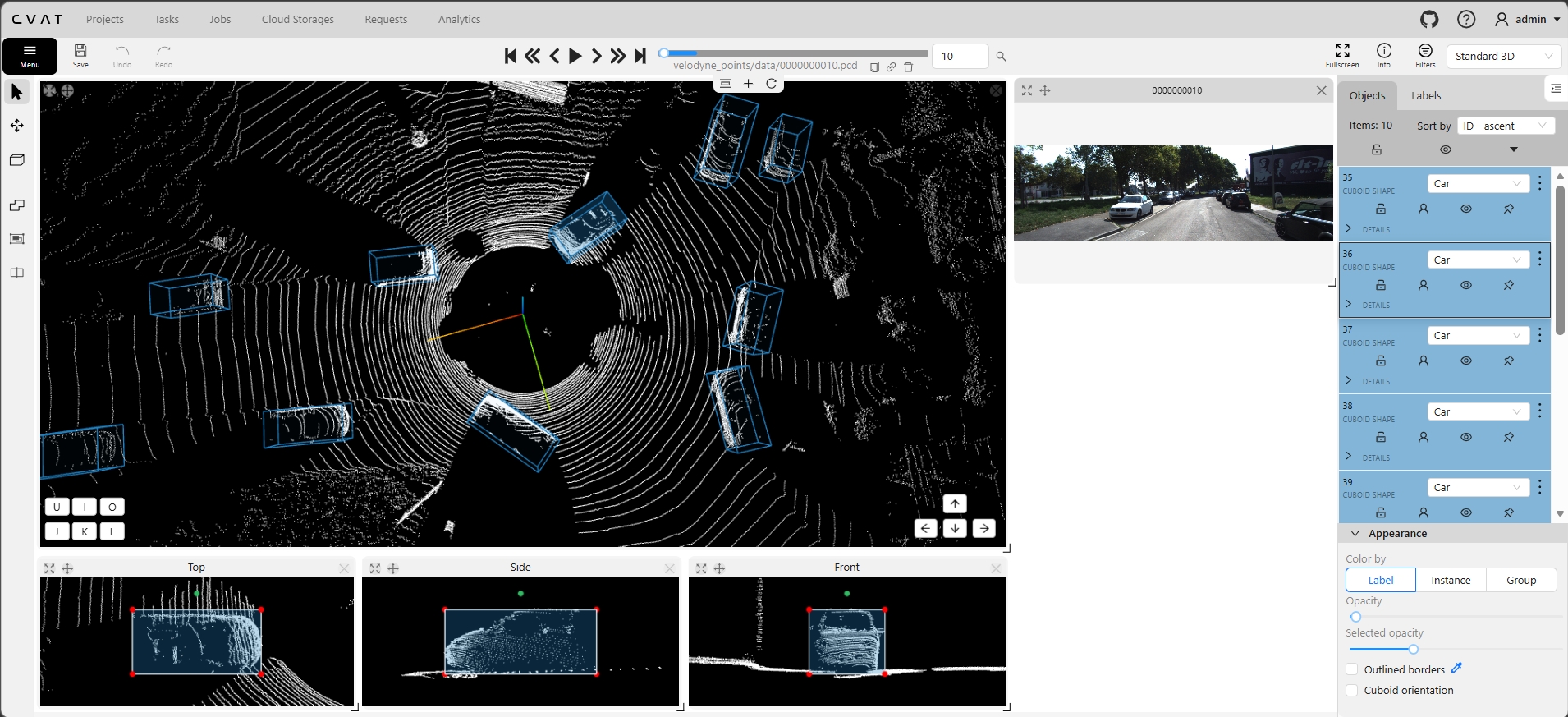
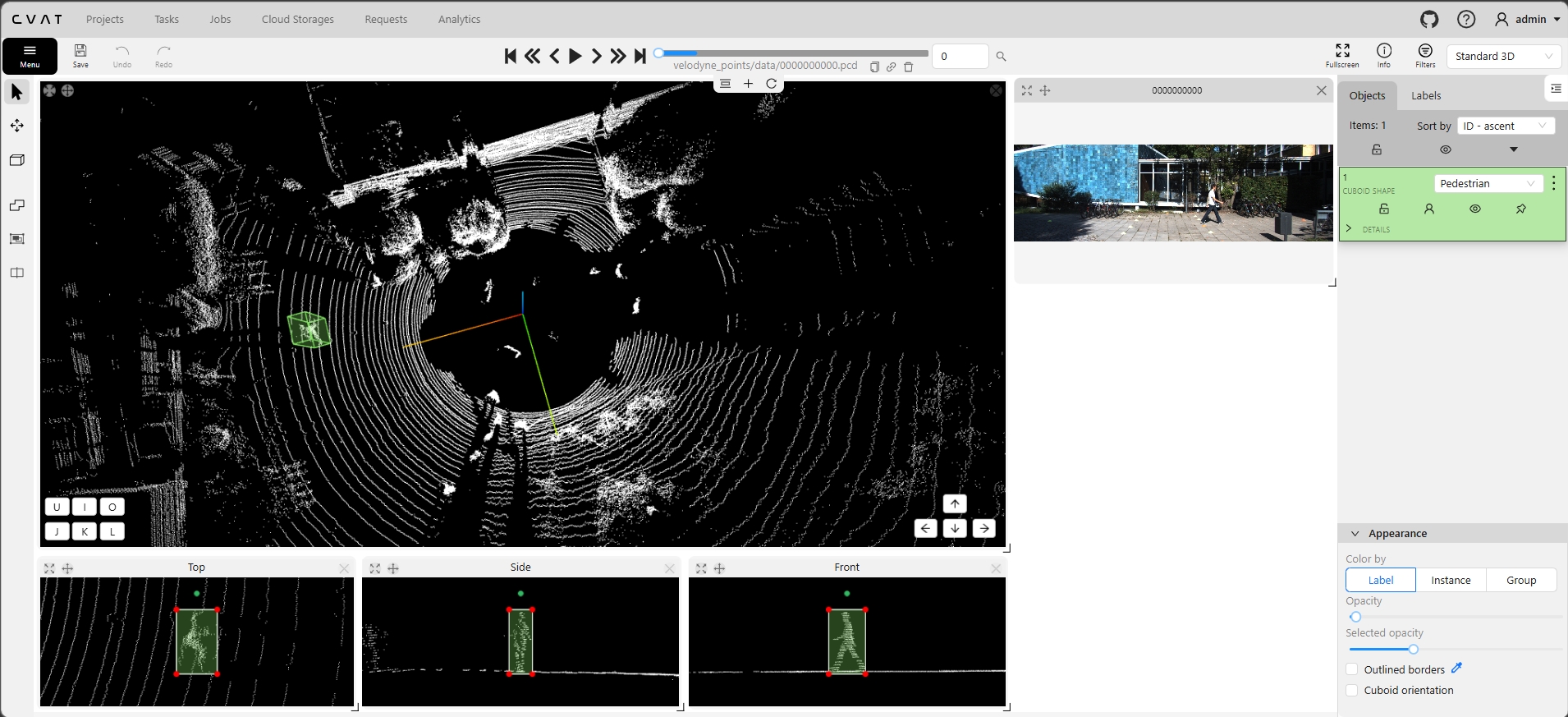
Left: Multi-object scene with 9 cuboids (Cars). Center: Dense traffic with 10 car objects. Right: Pedestrian detection with class-specific coloring. All frames show synchronized camera context and multi-view projections.
Annotation Progression
Scene complexity varies dramatically across frames — from a single pedestrian to dense multi-object intersections with 9+ vehicles. Our QA pipeline maintains consistent accuracy regardless of object count. Every cuboid is reviewed, every label verified.
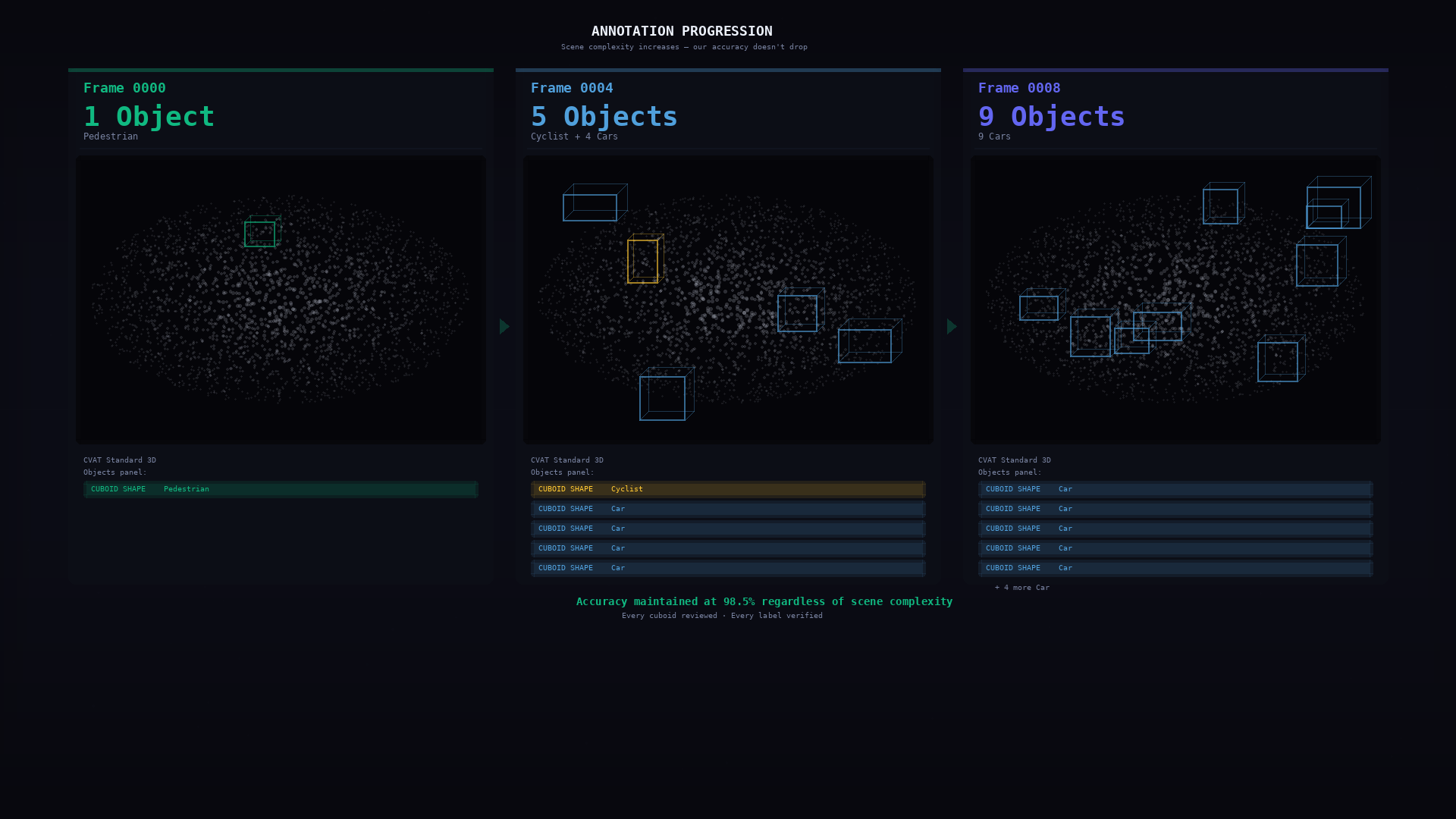
Frame 0000 (1 object) → Frame 0004 (5 objects) → Frame 0008 (9 objects). Accuracy maintained at 98.5% regardless of scene complexity. Every cuboid reviewed, every label verified.
Key insight: The hardest frames aren’t the ones with the most objects — they’re the ones with partial occlusions, long-range sparse points, and ambiguous class boundaries. Our annotators are trained to handle these edge cases with multi-view cross-validation: checking the 3D viewport, camera image, and side/top/front projections before committing each cuboid.
Before & After
Raw KITTI point cloud data arrives with no annotations — just millions of 3D points from the Velodyne LiDAR scanner. After our annotation pipeline, every object is enclosed in a precisely oriented 3D cuboid with class label, camera context is linked, and the data is exported in production-ready KITTI format.

Left: Raw velodyne_points data — no labels, no cuboids, no class separation. Right: Production-ready annotation — 6 object classes labeled, 3D cuboids with orientation, camera context linked, KITTI format exported.
How We Annotated This Project
Annotation Workflow
- Data ingestion: KITTI Raw .bin and .png files uploaded to self-hosted CVAT via Docker CLI
- Task creation: Frames split into manageable batches with velodyne_points + image_00 linked per frame
- 3D cuboid placement: Annotators draw cuboids in the 3D viewport using top/side/front projections for precision
- Class assignment: Each cuboid labeled with one of 6 object classes (Car, Pedestrian, Cyclist, Van, Truck, Misc)
- Camera cross-validation: Every cuboid checked against the synchronized camera image for class and boundary accuracy
Quality Assurance
- Stage 1 — Self-check: Annotator reviews own work against guidelines before submission
- Stage 2 — Peer review: Second annotator validates cuboid placement, class labels, and orientation
- Stage 3 — QA Lead final: Ibrahim Ouma (COO & QA Lead) performs final validation with IoU spot-checks
- Position accuracy target: Cuboid center within 10-30cm of true object position
- Orientation accuracy target: Within 5-10° of true heading
- Overall QA target: 98.5% accuracy across all frames
Who This Serves
This annotation capability directly supports perception teams building:
- Autonomous vehicles: Object detection and tracking for L2-L5 self-driving systems
- Robotics: Spatial awareness and obstacle avoidance for mobile robots and manipulators
- Spatial AI: 3D scene understanding for AR/VR, digital twins, and industrial inspection
- HD mapping: Static object annotation for high-definition map generation
Why KITTI format matters: KITTI is the most widely used benchmark for 3D object detection in autonomous driving. Supporting this format natively means our annotations plug directly into existing training pipelines — no conversion scripts, no format mismatches, no wasted engineering time on data wrangling.
Need 3D LiDAR Annotation?
Start with a free 500-frame pilot. Same CVAT infrastructure, same QA pipeline, same 98.5% accuracy guarantee. KITTI, nuScenes, or Waymo format — we match your pipeline.